patkit
Core Data Structures
PATKIT has hierarchy of core data structures which take care of representing files that contain raw or processed data and directories which organise the data files. The mapping is not exactly one-to-one as some data structures contain data from multiple files and the hierarchy of data structures is not necessarily exactly the same as the recommended directory structure (see Data management).
The basic idiom
Most core data structures consist (at least in principle) of three main branches: binary data, file information, and metadata. The binary data is the actual data, the file information tells where the data was read from, saved to, or should be saved to. The metadata helps interpret the data correctly.
Overview of data structures
Sessions are lists of Recordings which are collections of Modalities. A Recording is a single synchronised trial.
Modalities are the different, synchronised types of data recorded by a single program such as AAA recording sound, tongue ultrasound, and lip video. Finally, Modalities are collections of not only data but also Annotations of that data.
The below UML graph does not show all of the members of the classes, but rather only the most important ones. For a full description, please refer to the API documentation and the code itself. For a description of how the different classes are inherited from abstract base classes see PATKIT base classes.
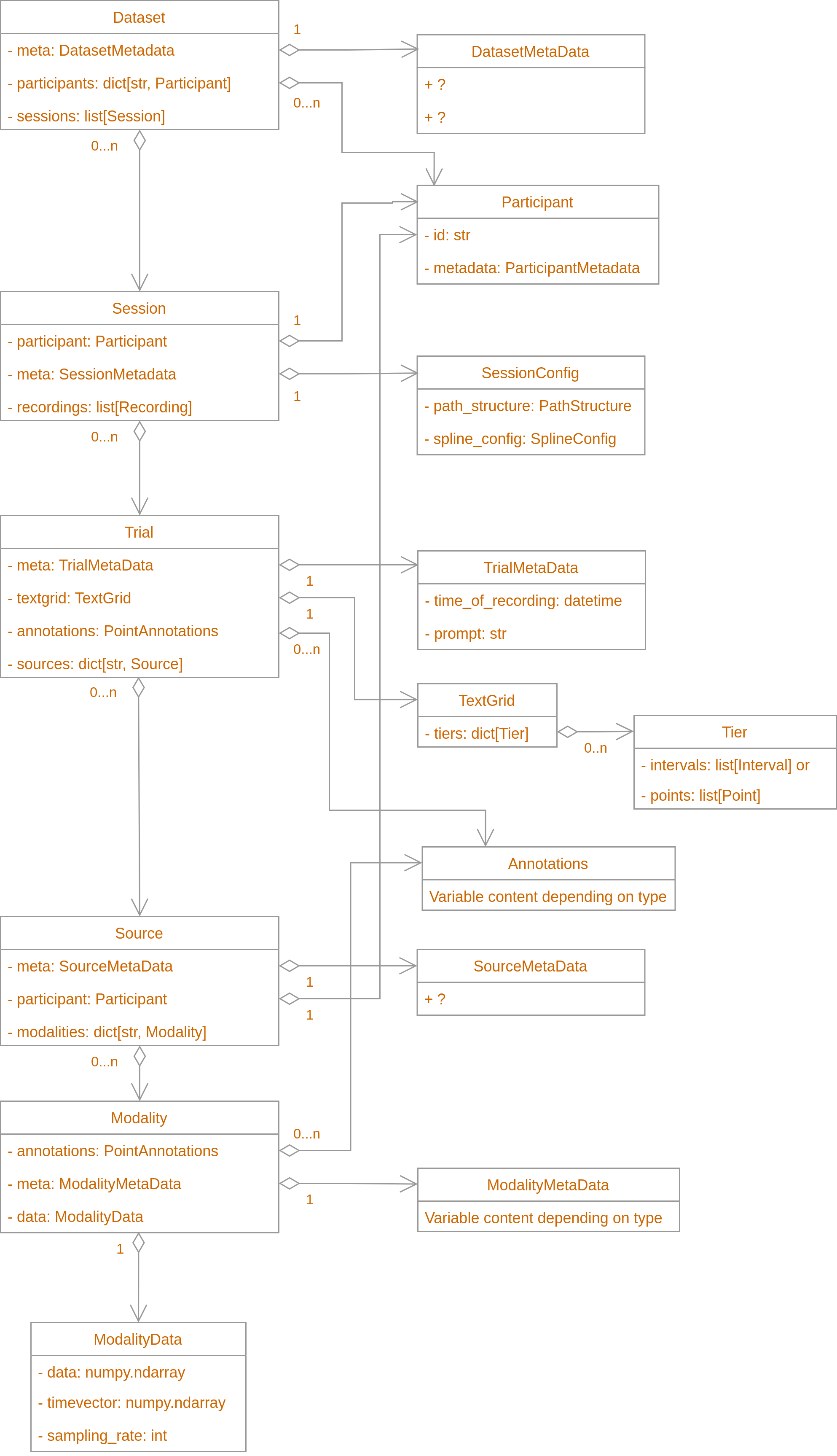
Structures as Concrete Collections
For ease of use all classes containing a list or a dict of their major components are Python lists and dicts of those components:
- Session is a list of Recordings.
- Session also contains a dictionary of Statistics, but is not a dictionary of Statistics in itself.
- Recording is a dictionary of Modalities.
- Recording – like Session – also contains a dictionary of Statistics, but is not a dictionary of Statistics in itself.
- Modalities are dictionaries of Annotations. This maybe slightly unintuitive, since the ‘beef’ of a Modality is its data. However, accessing the Annotations is also important and this makes it convenient.
Accessing the components in a Pythonic manner is encouraged, but setting them
that way may lead to problems. Use instead accessors like
Source.add_modality.
What Else is Contained: Metadata and Others
A Recording represents a single recording in an experiment. It consists of one or more Sources. The different data types – both recorded and derived – are represented by direct subclasses of Modality.
RecordingMetaData contains information on what was recorded and when, but not redundant information such as what kind of data. In addition, each Recording has a TextGrid (or rather a PatGrid, see API docs), which is a dict of Tiers which are lists of either Intervals or Points.
Besides being a dictionary of Annotations, each Modality contains metadata –
both general and specific to the type of Modality – and the actual data of the
Modality along with its timevector. These are primarily wrapped as a
ModalityData object but also available as Modality.data, Modality.timevector
and Modality.timeoffset for convenience.
The data field in ModalityData has a standardised axes order so that algorithms will work on unseen data. The general order is [time, coordinate axes and data types, data points] and further structure. For example stereo audio data would be [time, channels] or just [time] for mono audio. For a more complex example, splines from AAA have [time, x-y-confidence, spline points] or [time, r-phi-confidence, spline points] for data in polar coordinates.
A special kind of data is represented by Statistic, which can be contained (in dictionaries) by Session, and Recording. Statistics represent time invariant derived data such as an average over a Recording.
Base classes and inheritance
There are some abstract base classes which all of the core data structures inherit from. These are described in Base classes.
Most of the core structures inherit from these base classes, and in the case of Modality the actual Modalities like MonoAudio, Video, etc derive from Modality by direct inheritance. As tempting as it might be, we do not ever make these inheritance trees deeper than that. This does lead to code duplication, but also keeps the functionality much, much more manageable.
Future Data Structures
A possible version of the core data structures is described in Future Core Data Structures.